Technical Approach
CAVIAR will develop the modules for assembling a vision system demonstrator
that goes from the sensor, through programmable bio-inspired processing
layers, to provide outputs for use in actuation. A long term application
goal of CAVIAR is to use the results in “Automatic Car Driving”.
However, for the purpose of the present proposal, the CAVIAR consortium
proposes to assemble a little demonstrator which would be “a small
robot following a ball”. The robot, equipped with a sensing retina,
a set of low level convolutional processing filters and high level processing
stages, segments the sensed images, identifies the ball and gives instructions
to center the ball on the retina. Adaptation is also part of CAVIAR, since
learning stages are included in the high-level processing layers. This set
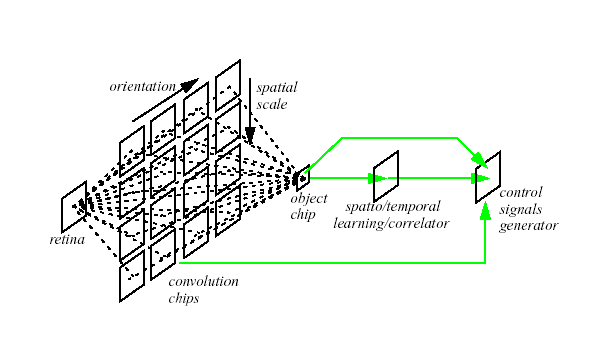
of modules comprises (see Fig. 2)
• A front-end
vision sensor that consists of a retina that outputs irradiances changes
in time in the AER-coded form.
• A general purpose programmable-kernel convolution module to implement
projection fields from layer to
layer. This module exploits the use of a special in-chip pulse width modulation
technique, which allows expansion to a multi-chip structure within the same
processing layer.
• A dimension-reduction competition module that uses a reduced-dimension
space to represent the low-level features extracted by the convolution system,
while making salient features to compete.
• A learning module that implements a spike-based learning rule that
is amenable to the incoming AER inputs. The learning will be based on spatio-temporal
statistics of the inputs.
These modules are all bound together by the AER infrastructure. All communication between the modules (including bidirectional communication) follows the AER protocol.
Demonstrator: To test the integrity of this perceptive-action vision system using the AER infrastructure, we will mount this system on a commercial robot and use the robot in a reference task.